Przeprowadzenie pełnej symulacji komputerowej ludzkiego mózgu wydaje się najprostszą drogą do osiągnięcia tak zwanej silnej sztucznej inteligencji (ang. artificial general intelligence – AGI). Mówiąc precyzyjniej, w tym przypadku należałoby dokonać emulacji mózgu, co wiązałoby się ze ścisłym odwzorowaniem (w ramach symulacji) struktury połączeń neuronalnych, wag synaptycznych oraz innych szczegółów morfologicznych pojedynczych neuronów i mózgu konkretnej osoby. Zagadnienie pozyskiwania danych wejściowych do emulacji mózgu jest obszerne i opiszę je niezależnie. Natomiast, tutaj chciałbym się skoncentrować na przeanalizowaniu aspektów obliczeniowych związanych z przeprowadzeniem symulacji mózgu ludzkiego.
Podstawową jednostką przetwarzającą informacje w mózgu jest neuron. Typowo, mózg dorosłego człowieka zawiera niecałe 
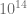
Chcąc przeprowadzić symulację mózgu należy zacząć od zdefiniowania modelu matematycznego pojedynczego neuronu. Neuron jest skomplikowaną komórką, przetwarzający sygnały elektrochemiczne poprzez złożone procesy fizykochemiczne zachodzące w jego błonie komórkowej. Zachowanie potencjału czynnościowego neuronu, kluczowego dla przetwarzania informacji w mózgu, można jednakże z dużą precyzją opisać za pomocą matematycznych modeli opierających się na analizie przewodności elektrycznej błony komórkowej. Najbardziej znanym przykładem takiego opisu jest model Hodgkina-Huxleya. Uproszczoną wersją modelu Hodkina-Huxleya jest zaproponowany w 2003 roku przez model Eugene M. Izhikevicha, opisywany przez układ dwóch równań różniczkowych.
Model neuronu Izhinkevicha. Model ten jest zredukowaną (poprzez zastosowanie metod matematycznych analizy układów dynamicznych) postacią modelu Hodkina-Huxleya. Opisywany jest przez układ dwóch równań różniczkowych:
wraz z warunkiem resetowania neuronu po wygenerowaniu impulsu nerwowego:
jeśli
mV to
i
.
W powyższych wzorach,
jest potencjałem czynnościowym,
jest zaś zmienną pomocniczą (tzw. membrane recovery variable). Natomiast
i
są parametrami modelu. Wartość potencjału synaptycznego pobudzającego określona jest przez
. Zachęcam do zabawy numerycznej z powyższym modelem.

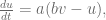
Załóżmy teraz, że chcielibyśmy przeprowadzić symulację mózgu ludzkiego opartego na neuronach opisywanych przez model Izhikevicha, rozszerzony o uwzględnienie wag synaptycznych. Zacznijmy od kwestii pamięci potrzebnej do przeprowadzenia takiej symulacji. Przypuśćmy, że do określenia każdej z wag potrzebujemy 1 bajt (8 bitów) informacji. To rozsądna wartość gdyż 1 B pozwala nam zapisać aż 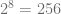
Przejdźmy teraz do mocy obliczeniowej. Posłużymy się tu definicją tak zwanych FLOPS-ów, czyli ilości operacji zmiennoprzecinkowych na sekundę.
FLOPS – Floating Point Operations Per Second. To liczba operacji na liczbach zmiennoprzecinkowych wykonywanych w trakcie sekundy przez daną jednostkę obliczeniową. Typowy rdzeń procesora wykonuje cztery takie operacje na jeden cykl, czyli 4 FLOPy. Procesor komputera na którym piszę ten tekst pracuje z częstotliwością 1,6 GHz i posiada dwa rdzenie. Każdy z rdzeni wykonuje więc 1,6 miliarda cykli na sekundę. Dostajemy stąd 4 FLOP
1,6 GHz = 6,4 GFLOP/s = 6,4 GFLOPS. Mnożąc ten wynik przez ilość rdzeni otrzymamy całkowitą moc obliczeniową mojego procesora, równą 12,8 GFLOPS (gigaflopsa). Przykład ten łatwo uogólnić w celu wyznaczenia mocy obliczeniowej bardziej złożonych jednostek obliczeniowych.
Model Hodkina-Huxleya wymaga około 1,2 miliona FLOPS-ów do symulacji w czasie rzeczywistym. Natomiast model Izhikevicha jedynie 13 000 FLOPS-ów w czasie rzeczywistym. Mnożąc to przez liczbę neuronów otrzymujemy około 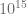

Dzisiejszy najlepszy superkomputer, chiński Sunway TaihuLight, dysponuje mocą właśnie około 100 PFLOPS. Najlepszy polski superkomputer Prometheus dysponuje mocą ponad 2 PFLOPS, wystarczającej więc do symulowania modelu mózgu ludzkiego

opartego o modele neuronów Izhikevicha. Całkowita moc pięciuset najlepszych superkomputerów świata osiąga dzisiaj wartość 1000 PFLOPS. Obserwuje się, że moc obliczeniowa superkomputerów zwiększa się o czynnik około 
Żyjemy w czasach w których moce obliczeniowe pojedynczych superkomputerów stają się wystarczające do symulowania modeli ludzkich mózgów. Nie tylko staje się to możliwe ale w coraz większym stopniu już się to dzieje. Pozwolę sobie, w tymi miejscu, przytoczyć kilka reprezentatywnych przykładów takich badań:
1) Izhikevich. W 2005-tym roku przeprowadził on symulację modelu mózgu zbudowanego z 
2) Human Brain Project (HBP). Celem projektu jest pełna symulacja mózgu ludzkiego do roku 2023. HBP jest flagowym projektem w ramach H2020, finansowanym ze środków Unii Europejskiej. Projekt wyspecjalizował się w symulowaniu kolumn neuronalnych. Wykorzystywane modele neuronów są niezwykle precyzyjne, natomiast dane wejściowe pochodzą z obrazowania układów biologicznych. Obecnie w projekcie wprowadzane są tak zwane komputery neuromorficzne. Najbardziej rozbudowane symulacje w ramach HBP dotyczyły około miliona neuronów, każdy o niezwykle wysokim poziomie precyzji modelowania.
3) Spaun. W 2012-tym roku przeprowadzono symulację modelu zawierającego 2.5 miliona neuronów. Symulacja została wyposażona w zmysł wzroku (poprzez jedno oko) oraz w zdolności motoryczne (poprzez ramię). Zaobserwowano zachowania podobne do ludzkich. Symulacje była w stanie przeprowadzić osiem niezależnych percepcyjnych, motorycznych i poznawczych zadań w dowolnej kolejności.
4) SyNAPSE. Finansowany przez DARPA projekt symulacji mózgu oparty o procesory neuromorficzne. W ramach tego projektu przeprowadzono symulację modelu mózgu zawierającego 500 miliardów neuronów, czyli około pięć razy więcej niż w mózgu ludzkim. Jednakże, bazowano na uproszczonych modelach neuronów, podobnych do tych wykorzystanych w symulacjach Izhikevicha.
Największym wyzwaniem stojącym przed symulacjami ludzkiego mózgu jest obecnie wprowadzenie odpowiednich danych początkowych. Dzisiaj są one albo generowane losowo z uwzględnieniem pewnych cech architektury mózgu albo częściowo pozyskiwane z danych obrazowania tkanki mózgu zwierząt (jak to ma np. miejsce w HBP). Możemy się jednakże spodziewać, że rozwój technik zarówno inwazyjnego jak i bezinwazyjnego obrazowania tkanki mózgowej umożliwi w ciągu dekady przeprowadzenie realistycznych emulacji mózgu ludzkiego. Ale o tym, tak jak już wspomniałem, innym razem. Niecierpliwym zaś rekomenduję raport Brain Emulation: A Roadmap opublikowany, w ramach działającego na Uniwersytecie w Oksfordzie Future of Humanity Institute, przez Andersa Sandberga i Nicka Bostroma.
Bez wątpienia, wchodzimy obecnie w epokę petabajtów jak i petaFLOPS-ów. Są to właśnie te skale pamięci i mocy obliczeniowej które są potrzebne do przeprowadzenia realistycznych symulacji modeli ludzkiego mózgu. Symulacje te stają się na naszych oczach faktem a ich precyzja będzie rosnąć, uwzględniając coraz to większą liczbę szczegółów budowy morfologicznej mózgu i samych neuronów. Sięgając dalej w przyszłość, prowadzone symulacje wykroczą poza przypadek ludzkiego mózgu, rozszerzając jego możliwości poznawcze co w konsekwencji może urzeczywistnić ideę tak zwanej superinteligencji.
© Jakub Mielczarek

[…] najbardziej obiecującą (i już najbardziej zaawansowaną) drogę do osiągnięcia AGI uważam symulacje ludzkiego mózgu. Badania zmierzające w tym kierunku prowadzone są m.in. w ramach flagowego projektu Komisji […]
[…] inteligencji i symulacji ludzkiego mózgu. Można o tym poczytać w moich wcześniejszych wpisach O symulacjach ludzkiego mózgu i Dwanaście technologii jutra, gdzie m.in. przywołuję prowadzone obecnie symulacje wykonywane za […]
[…] Obliczenia te oparte są na matematycznym opisie działania neuronów wg modelu Hodgkina-Huxleya (szczegóły dla […]